
Yandex SpeechKit
Сервис распознаёт и синтезирует речь на нескольких языках.
SpeechKit — речевые технологии голосового помощника Алиса, адаптированные для использования в ваших бизнес-решениях.
Распознавание с учётом контекста
Синтез в реальном времени
Поддержка трёх языков
Премиум-голоса
Прозрачное ценообразование
Решайте свои задачи с Yandex SpeechKit
Автоматизация работы колл-центров
Телемаркетинговые кампании
Управление приложением
Озвучивание курсов и вебинаров
Повышение доступности для слабовидящих пользователей
Готовые бизнес-решения на основе Yandex SpeechKit
Узнайте о задачах, которые голосовые роботы эффективно решают уже сейчас.
Истории компаний




Вопросы и ответы
Как использовать SpeechKit?
Сервис работает через HTTP API. Всё, что нужно для работы, вы сможете найти в документации. Начните знакомство с сервисом самостоятельно или обратитесь к нам. Мы подберём партнёра, который разработает решение специально для вашей задачи.
Сервис работает через HTTP API. Всё, что нужно для работы, вы сможете найти в документации. Начните знакомство с сервисом самостоятельно или обратитесь к нам. Мы подберём партнёра, который разработает решение специально для вашей задачи.
Зачем регистрироваться в консоли Yandex.Cloud?
Для использования API необходимо получить идентификатор (IAM-токен или API-ключ). Этот идентификатор привязан к учетной записи в облаке.
Для использования API необходимо получить идентификатор (IAM-токен или API-ключ). Этот идентификатор привязан к учетной записи в облаке.
Что такое модель распознавания?
Модели распознавания — нейронная сеть, которая обучена распознавать речь на определенном языке. Для обучения моделей используются массивы данных из сервисов и приложений Яндекса. Это позволяет постоянно улучшать качество распознавания.
Модели распознавания — нейронная сеть, которая обучена распознавать речь на определенном языке. Для обучения моделей используются массивы данных из сервисов и приложений Яндекса. Это позволяет постоянно улучшать качество распознавания.
Какие форматы аудио поддерживает Yandex SpeechKit для распознавания?
Сервис позволяет распознавать аудио в форматах LPCM и OggOpus.
Сервис позволяет распознавать аудио в форматах LPCM и OggOpus.
Мегапроект: расшифровщик аудио в текст… через облако Яндекса!
Мы уже использовали нейросети Яндекса, когда делали свой орфонейрокорректор — он автоматически исправляет все ошибки и опечатки, когда вы набираете текст. Теперь перейдём на уровень выше — используем искусственный интеллект для распознавания голоса в аудиозаписях. И для этого мы воспользуемся облачным сервисом Яндекса, потому что можем. Вы тоже.
Для чего это нужно
Смысл такой: если нужно перевести аудиозапись в текст, можно это сделать очень быстро с помощью нейросетей. Яндекс в этом всяко преуспел, и мы теперь можем этим воспользоваться в своё удовольствие.
Если вы редактор или автор, вам нужно часто общаться с экспертами, чтобы получить необходимую информацию для своей работы. Можно всё конспектировать на ходу, а можно записать на диктофон и потом перевести в текст за 10 минут.
Если коллега вам оставил длинное голосовое сообщение, текст которого нужно разместить на сайте, то можно набрать всё руками или отдать эту задачу компьютеру.
Если вы студент и не хотите конспектировать лекции по гуманитарным наукам, запишите их на телефон, и нейронка переведёт их в текст. У вас будут самые полные лекции, и вся группа будет бегать за вами перед экзаменом.
В некоторых вебинарах или видео на YouTube есть классная информация, но каждый раз приходится их смотреть и перематывать, чтобы найти нужное. Выход простой: берём видео, вырезаем оттуда звук, отправляем в сервис распознавания и получаем готовый текст, с которым работать гораздо проще.
Что будем использовать
Возьмём сервис Yandex SpeechKit — он позволяет распознать или озвучить любой текст на нескольких языках. Именно на этом движке работает голосовой помощник «Алиса»: она использует его, чтобы понимать, что вы говорите, и говорить что-то в ответ.
SpeechKit — часть «Яндекс.Облака», большого ресурса, который умеет решать много задач. Например, кроме работы с текстом и голосом «Облако» может предоставить виртуальную вычислительную машину и хранилище данных, работать с Docker-образами, защищать от хакерских атак, управлять базами данных и много чего ещё.
Так как всё это — серьёзные технологии для программистов и IT-спецов, многое нужно будет делать в командной строке. Для этого мы сейчас покажем каждый шаг и объясним, для чего именно мы это делаем. В результате научимся отправлять файлы в «Облако» и получать оттуда готовый текст.
Вся первая часть проекта у нас как раз и будет про настройку «Яндекс.Облака» и подготовку к работе.
Условия и ограничения
Распознавание речи — платная услуга, но Яндекс даёт 60 дней и 3000 ₽ для тестирования. За эти деньги можно распознать 83 часа аудио — больше трёх суток непрерывного разговора. Это очень много: за время подготовки этой статьи и тестирования технологии мы потратили 4 рубля за 3 дня.
Если отправлять файлы с записью больше минуты, то одна секунда аудио стоит одну копейку. Чтобы распознать запись длиной в час, нужно 36 рублей. Это примерно в 20 раз дешевле, чем берут транскрибаторы — люди, которые сами набирают текст на слух, прослушивая запись.
Нейросеть часто понимает, когда текст нужно разбить на абзацы, но делает это не всегда правильно.
Ещё она не ставит запятые, тире и двоеточия. Максимум, что она делает — ставит точку в конце предложения и начинает новое с большой буквы. Но при этом почти все слова распознаются правильно, и отредактировать такой текст намного проще, чем набирать его с нуля.
Последнее — из-за особенностей нашей речи и произношения SpeechKit может путать слова, которые звучат одинаково (код — кот) или ставить неправильное окончание («слава обрушилось на него неожиданно»). Решение простое: прогоняем такой текст через орфонейрокорректор и всё в порядке. Одна нейронка исправляет другую — реальность XXI века 🙂
Регистрация в «Облаке»
Для этого нам понадобится Яндекс-аккаунт: заведите новый, если его у вас нет, или войдите в него под своим логином.
Если аккаунт уже есть — переходим на страницу сервиса cloud.yandex.ru и нажимаем «Подключиться»:

На следующем шаге подтверждаем согласие с условиями, и мы у цели:

На главной странице «Облака» активируем пробный период, чтобы бесплатно использовать все возможности сервиса, в том числе и SpeechKit:

Единственное, что нам осталось из формальностей, — заполнить данные о себе и привязать банковскую карту. С неё спишут два рубля и сразу вернут их, чтобы убедиться, что карта активна. Она нужна для того, чтобы пользоваться сервисами после окончания пробного периода. Если вам это будет не нужно — просто удалите карту, когда закончите проект.
Когда всё будет готово, вы попадёте на главную страницу сервиса, где увидите что-то подобное:
Командная строка Яндекса
С её помощью мы сможем получать нужные ключи доступа, чтобы отправлять файлы с записями на сервер для обработки.
Весь процесс установки мы опишем для Windows. Если у вас Mac OS или Linux, то всё будет то же самое, но с поправкой на операционную систему. Поэтому если что — читайте инструкцию.
Для установки и дальнейшей работы нам понадобится PowerShell — это программа для работы с командной строкой, но с расширенными возможностями. Запускаем PowerShell и пишем там такую команду:
iex (New-Object System.Net.WebClient).DownloadString(‘https://storage.yandexcloud.net/yandexcloud-yc/install.ps1’)
Она скачает и запустит установщик командной строки Яндекса. В середине скрипт спросит нас, добавить ли путь в системную переменную PATH, — в ответ пишем Y и нажимаем Enter:
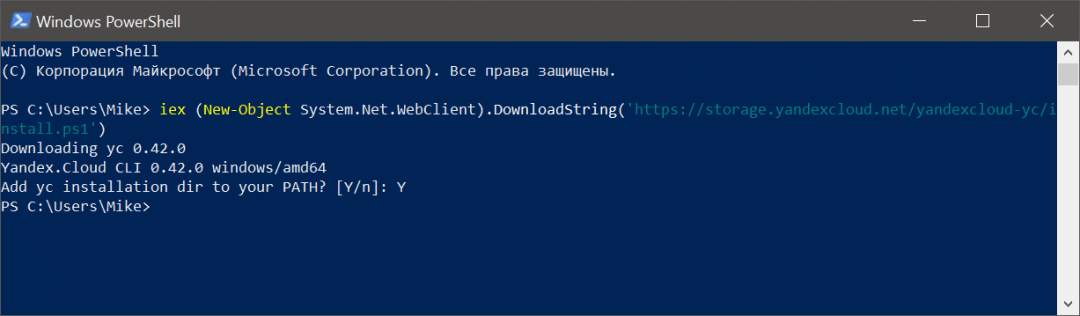
Командная строка Яндекса установлена в системе, закрываем PowerShell и запускаем его заново. Теперь нам нужно получить токен авторизации — это такая последовательность символов, которая покажет «Облаку», что мы — это мы, а не кто-то другой.
Переходим по специальной ссылке, которая даст нам нужный токен. Сервис спросит у нас, разрешаем ли мы доступ «Облака» к нашим данным на Яндексе — нажимаем «Разрешить». В итоге видим страницу с токеном:
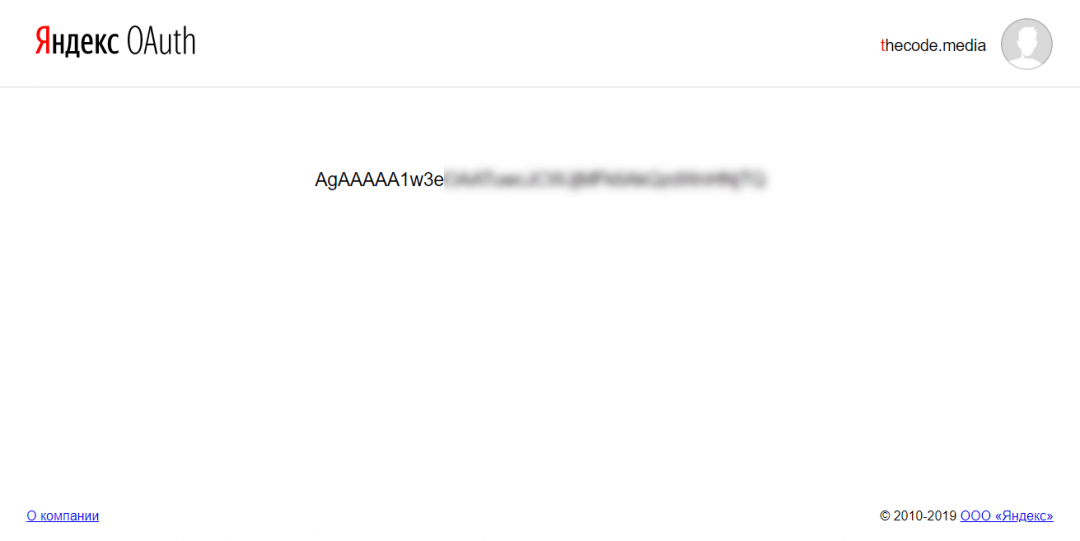
Теперь нужно закончить настройку командной строки Яндекса, чтобы можно было с ней полноценно работать. Для этого в PowerShell пишем команду:
Когда скрипт попросит — вводим токен, который мы только что получили:
Настраиваем доступ
Есть два способа работать с сервисом SpeechKit: через IAM-токен, который нужно запрашивать заново каждые 12 часов, или через API-ключ, который постоянный и менять его не нужно. Мы будем работать через ключ, потому что так удобнее.
Чтобы его получить, нам нужен сервисный аккаунт в «Облаке». Создадим его так.
1. Заходим в консоль управления и нажимаем на единственную папку в нашем облаке:
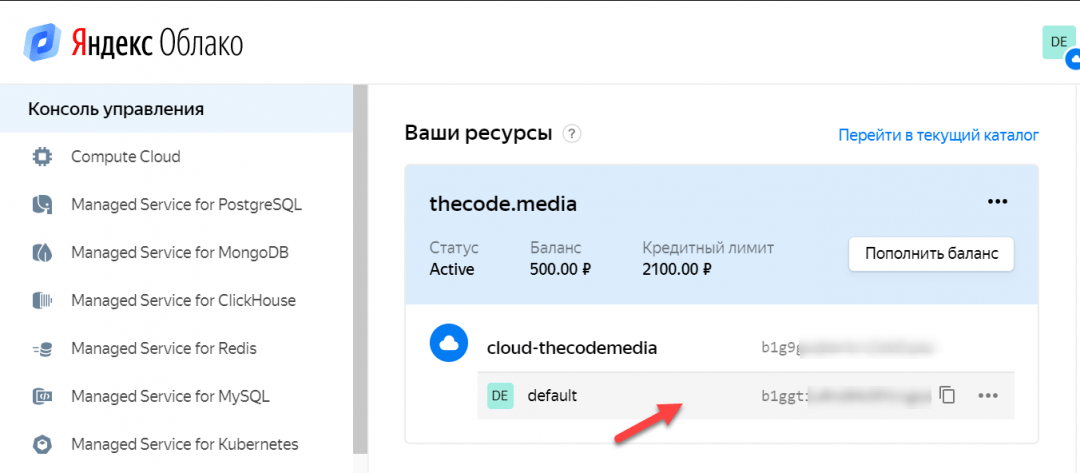
2. Выбираем «Сервисные аккаунты» → «Создать»:
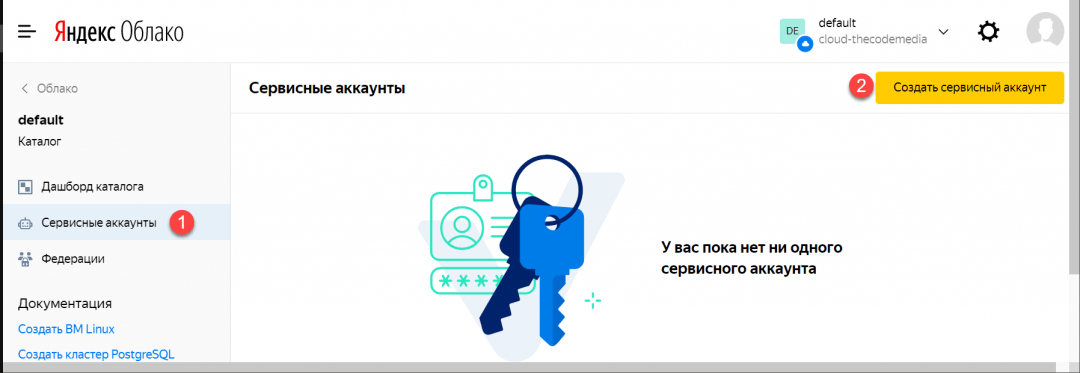
3. Вводим имя (какое понравится), затем нажимаем «Добавить роль» и выбираем «editor»:
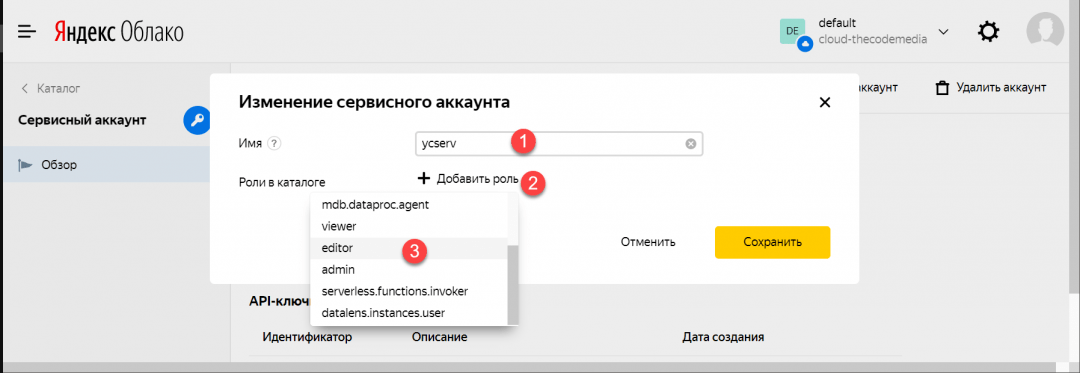
4. Заходим в сервисный аккаунт, который только что создали:
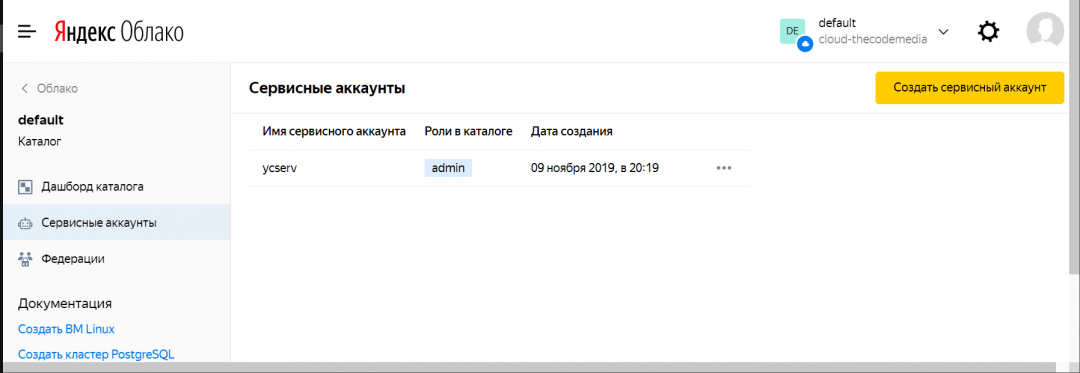
5. Нажимаем на кнопку «Создать новый ключ» и выбираем пункт «Создать API-ключ»:
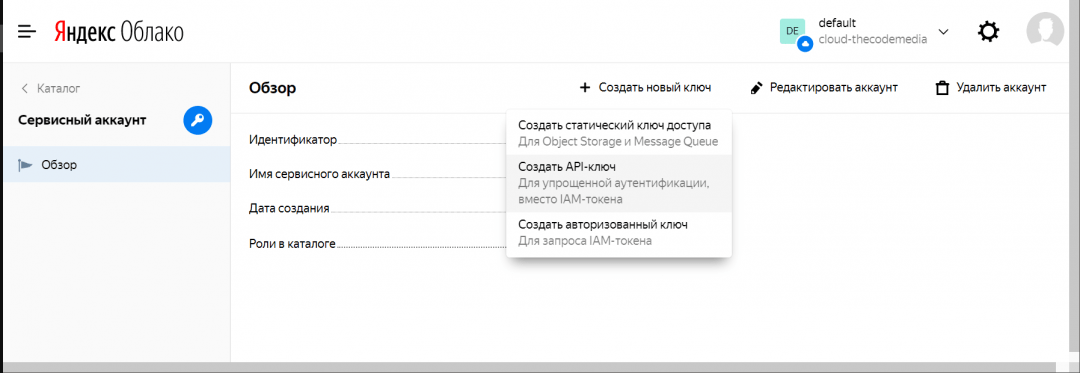
Сервис спросит про описание — можно ничего не заполнять.
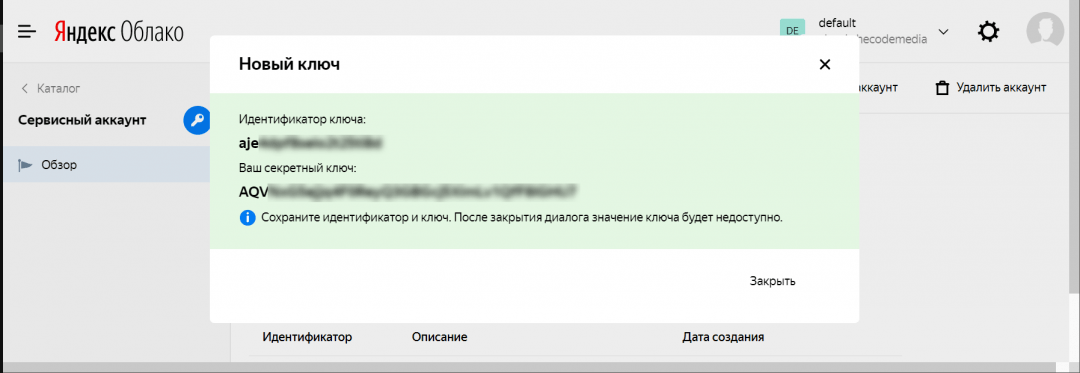
6. Сохраняем отдельно секретный ключ — он выдаётся только один раз и восстановить его нельзя. Выделяем, копируем и сохраняем в безопасное место:
Что дальше
Поздравляем — самое сложное позади. Дальше будет проще: мы напишем программу на Python, которая будет отправлять на сервер запрос на расшифровку и получать в ответ готовый текст. Ту би континьюд.
Пять способов как превратить голос в текст
Кто не мечтал отдать компьютеру диктофонную запись и через некоторое время получить готовый текст? Сегодня мы расскажем, как это сделать.
Способ первый: по старинке
Садимся за компьютер, одеваем наушники, включаем диктофонную запись. И начинаем расшифровывать, быстро-быстро стуча по клавишам. На сегодня это самый надежный способ. И самый медленный. Если собеседник говорит быстро или плохое качество записи, вам придется не раз перематывать диктофонную запись назад. В среднем вам придется потратить в два-три раза больше времени, чем длится запись, которую вы расшифровываете.
Совет: для прослушивания записи используйте аудиоплеер AIMP. В нем можно замедлить скорость воспроизведения через Менеджер звуковых эффектов. Голос при этом будет искажен, зато вам реже понадобится перемотка назад. Если же запись очень тихая и максимальная громкость не помогает, можно воспользоваться нормализацией записи (специальный способ увеличения громкости).
Способ второй: начитываем сами
Современные технологии распознавания речи продвинулись далеко. Но они еще не справляются с диктофонными записями, где присутствуют посторонние шумы, собеседника слышно тихо или плохо. Зато они хорошо распознают голос с микрофона. Воспользуемся этим.
Устанавливаем Яндекс.Диск 3.0 , вместо с ним установится утилита Заметки в Яндекс.Диске. Открываем ее и нажимаем на значок микрофона. Скажите несколько фраз. Текст распознается почти без ошибок. Из знаков препинания здесь только точки. Но и этого достаточно.
Теперь запускайте диктофонную запись в наушниках и одновременно начитывайте ее своим голосом в микрофон (можно использовать встроенный в наушники). Так вы получите вполне сносный к дальнейшей обработке текст. Разумеется, вы должны уметь быстро воспринимать чужую речь и превращать ее в свою.
Совет: можете также использовать другие сервисы, базирующиеся на разработках Google — GoogleSpeech , Speechpad или Speechlogger . Эти сайты нужно запускать в браузере Google Chrome.
Способ третий: грузим YouTube
Ютуб умеет автоматически создавать субтитры. Вы можете попробовать загрузить в сервис диктофонную запись и подождать, пока сформируются субтитры (т.е. распознается ваш текст). Процесс долгий и каким будет результат, вы узнаете не сразу. Поэтому этот способ мы не рекомендуем. Из плохой записи вы все равно не получите приличный результат.
Способ четвертый: полная автоматика
Если у вас хорошая диктофонная запись, где голос звучит ровно, ясно и четко, нет посторонних шумов, можно попробовать использовать вышеупомянутые программы распознавания речи. Но вначале схитрим: сделаем так , чтобы аудиозапись, воспроизводимая с компьютера, была автоматическая направлена на микрофон.
Для этого нам нужно зайти в настройки Windows. В панели Звуки заходим во вкладку Запись , где отключаем Микрофон и другие входы и включаем Стерео микшер . Если вы не видите этих устройств, попробуйте включить показ отключенных и отсоединенных устройств.
После этого включаем сервис рапознавания речи (например, от Яндекса) и включаем воспроизведение диктофонной записи. Практически сразу же начнется распознавание и перевод голоса в текст. В наушниках аудиозапись вы слышать не будете. Не переживайте, так и должно быть.
Если не получается, нужно скачать и установить виртуальное устройство VB-CABLE Virtual Audio Device ( скачать драйвер можно здесь ). Теперь в панели Звуки включаем CABLE Input и CABLE Output (в вкладках Воспроизведение и Запись) и отключаем все остальные включенные устройства.
Учтите, хороший результат вы можете получить только с качественной аудиозаписью. Вот что может получится с плохой — смотрите на скриншоте. Если что «масик мама» — это «массив маймо» (Massive MIMO).
Способ пятый: дождаться будущего
Пройдет еще несколько лет и проблема расшифровки аудиозаписей исчезнет. Искусственный интеллект научится отделять зерна от плевел (т.е. голос от шума), улучшится распознавание плохой речи. Надо только подождать.