
Превращаем картинку в звук
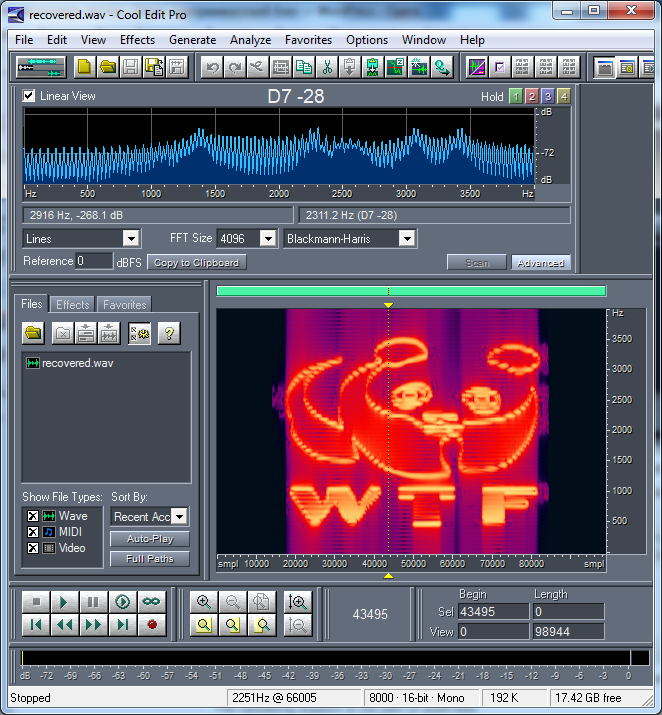
Попробуем заняться довольно бессмысленным занятием, а именно получением звука с определенной спектрограммой. Вдруг ряды любителей ЭГФ сократятся, не в обиду фанатам фильма «Белый шум» 🙂
Итак, начнем с моделирования на Matlab. Хотим алгоритм, позволяющий переводить звук в картинку-спектрограмму и обратно. Логично будет начать с вычисления спектрограммы, по которой будет вычисляться изображение.
Чтобы не делать того, что уже давно сделано за нас другими, здесь используется функция enframe из библиотеки voicebox,предназначенной для решения разнообразных задач при распознавании речи. Функция enframe как раз и позволяет нарезать сигнал на кадры с заданным шагом. Длину кадра мы берем мы берем равным длине преобразования Фурье(FFTLEN= 256), а шаг — половина этого значения(128). Все в лучших традициях 🙂 На каждый кадр накладывается окно Хэннинга для устранения боковых лепестков при вычислении ДПФ. Так как кадры идут с половинным перекрытием, то при наложении окна, сумма весов под перекрывающимися участками равна 1 и мы легко можем восстановить сигнал в половине кадра по двум соседним кадрам.
Для фразы «Почему не стоит пользоваться аутсорсингом в странах с дешевой рабочей силой» получилась следующая спектрограмма:
Исходный звук был такой (с онлайн-плеером для .wav файлов пока не разобрался)
Естественно, что однозначно мы восстановить сигнал не сможем. При получении изображения каждый отсчета спектрограммы берется модулем комплексного значения — теряется информация о фазе. Поэтому, если просто собрать восстановленные половинки, то будут две проблемы:
- Будут четко видны границы кадров(так как все гармоники будут с одинаковой фазой в каждом кадре
- Составляющие с нечетным числом периодов синусоиды не склеятся гладко
Первая проблема пока остается, для решения второй я пытался подкручивать фазу при сборке полукадров — через один полукадр. Делалось это примерно так:
После восстановления, получилось вот что
И теперь осталось только написать небольшую функцию получения спектрограммы из картинки. Изображение превращаем в черно-белое, а затем масштабируем до нужного размера по высоте.
Немножко сжульничал, строчкой «image = 1-image;» сделав негативное изображение, чтобы наш мишка выглядел яркими пятнами на темном, а не наоборот. Иначе — было бы слишком много шума.
Полученный звук, естественно, для сохранения психического равновесия слушать категорически не рекомендуется… Желающие могут поподбирать картинку, чтобы получить что-нибудь похожее на транс-музыку от Майкрософта.
Исходный код и все необходимое из статьи можно скачать отсюда.
Преобразуем изображение в звук — что можно услышать?
В недавней публикации здесь на сайте описывалось устройство, позволяющее незрячим людям «видеть» изображение, преобразуя его с помощью звуковых волн. С технической точки зрения, в той статье не было никаких деталей вообще (а вдруг украдут идею за миллион), но сама концепция показалась интересной. Имея некоторый опыт обработки сигналов, я решил поэкспериментировать самостоятельно.
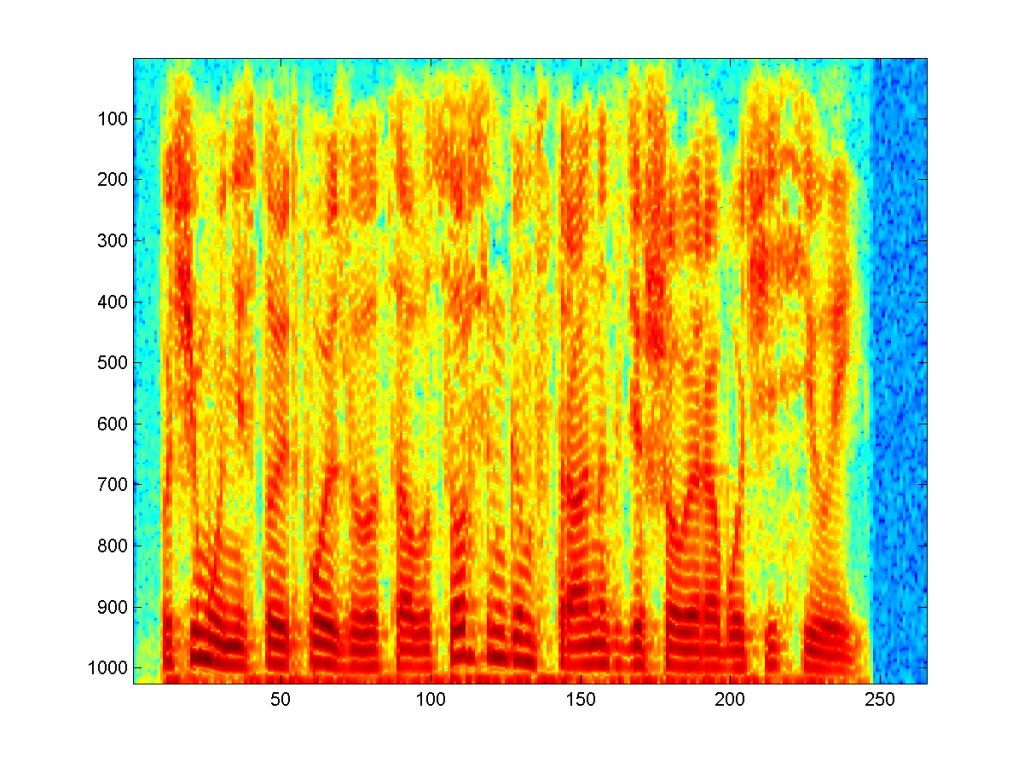
Что из этого получилось, подробности и примеры файлов под катом.
Преобразуем 2D в 1D
Первая очевидная задача, которая нас ожидает — это преобразовать двухмерное «плоское» изображение в «одномерную» звуковую волну. Как подсказали в комментариях к той статье, для этого удобно воспользоваться кривой Гильберта. 
Она по своей сути похожа на фрактал, и идея в том, что при увеличении разрешения изображения, относительное расположение объектов не меняется (если объект был в верхнем левом углу картинки, то он останется там же). Различные размерности кривых Гильберта могут дать нам разные изображения: 32×32 для N=5, 64×64 для N=6, и так далее. «Обходя» изображение по этой кривой, мы получаем линию, одномерный объект.
Следующий вопрос это размер картинки. Интуитивно хочется взять изображение побольше, но тут есть большое «но»: даже картинка 512х512, это 262144 точек. Если преобразовать каждую точку в звуковой импульс, то при частоте дискретизации 44100, мы получим последовательность длиной в целых 6 секунд, а это слишком долго — изображения должны обновляться быстро, например с использованием web-камеры. Делать частоту дискретизации выше бесмысленно, мы получим ультразвуковые частоты, неслышимые ухом (хотя для совы или летучей мыши может и пойдет). В итоге методом научного тыка было выбрано разрешение 128х128, которое даст импульсы длиной 0.37c — с одной стороны, это достаточно быстро чтобы ориентироваться в реальном времени, с другой вполне достаточно, чтобы уловить на слух какие-то изменения в форме сигнала.
Обработка изображения
Первым шагом мы загружаем изображение, преобразуем его в ч/б и масштабируем до нужного размера. Размер изображения зависит от размерности кривой Гильберта.
Следующим шагом формируем звуковую волну. Тут разумеется, может быть великое множество алгоритмов и ноухау, для теста я просто взял яркостную составляющую. Разумеется, наверняка есть способы лучше.
Из кода, надеюсь, все понятно. Функция coordinates_from_distance делает за нас всю работу по преобразованию координат (х, у) в расстояние на кривой Гильберта, значение яркости L мы инвертируем и преобразуем в цвет.
Это еще не все. Т.к. на изображении могут быть большие блоки одного цвета, это может привести к появлению в звуке «dc-компоненты» — длинного ряда отличных от нуля значений, например [100,100,100. ]. Чтобы их убрать, применим к нашему массиву high-pass filter (фильтр Баттерворта) с частотой среза 50Гц (совпадение с частотой сети случайно). Синтез фильтров есть в библиотеке scipy, которым мы и воспользуемся.
Последним шагом сохраним изображение. Т.к. длина одного импульса короткая, мы повторяем его 10 раз, это будет на слух более приближено к реальному повторяющемуся изображению, например с веб-камеры.
Результаты
Вышеприведенный алгоритм, разумеется, совсем примитивный. Я хотел проверить три момента — насколько можно различать разные несложные фигуры, и насколько можно оценить расстояние до фигур.

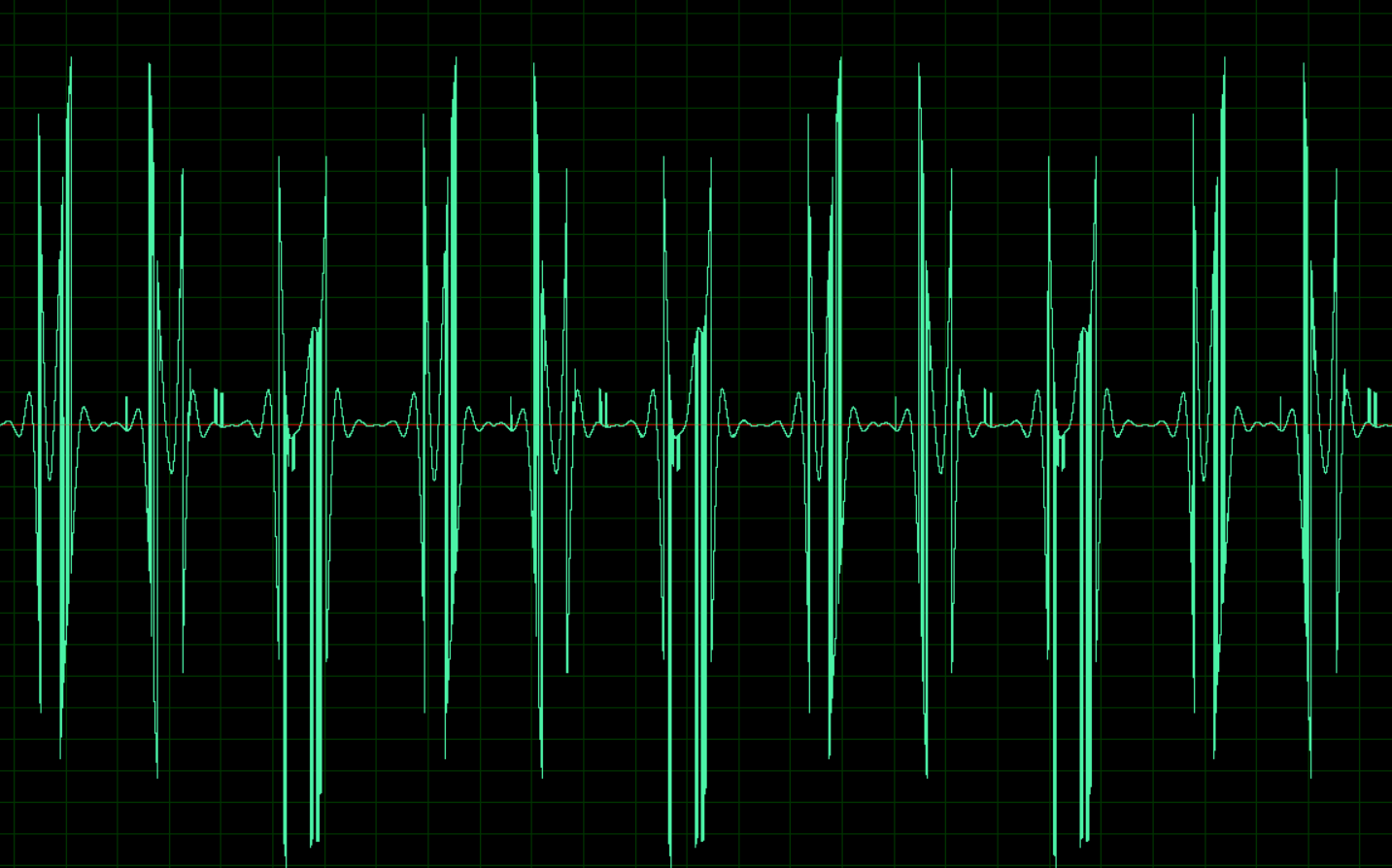
Изображению соответствует такой звуковой сигнал: 

Идея этого теста — сравнить «звучание» объекта другой формы. Звуковой сигнал: 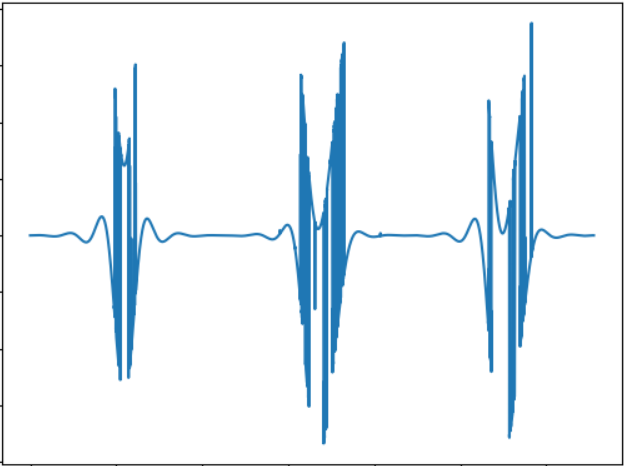
Можно заметить, что звучание действительно другое, и на слух разница есть.

Идея теста — проверить объект меньшего размера. Звуковой сигнал: 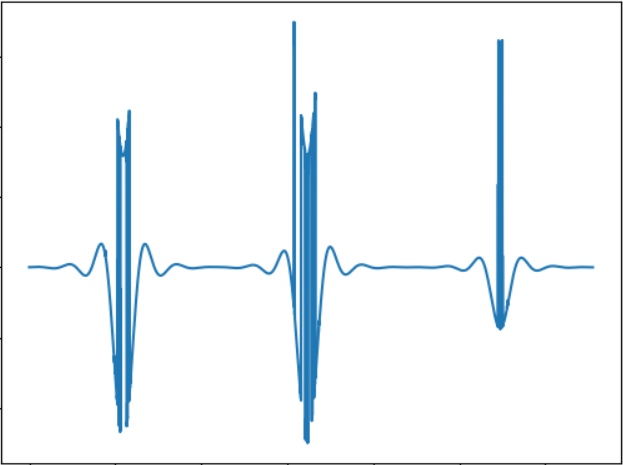
В принципе, чем меньше размеры объекта, тем меньше будет «всплесков» в звуке, так что зависимость тут вполне прямая.
Как подсказали в комментариях, можно использовать преобразование Фурье для непосредственной конвертации картинки в звук. Сделанный по-быстрому тест показывает такие результаты (картинки те же):
Тест-1: cloud.mail.ru/public/2C5Z/5MEQ8Swjo
Тест-2: cloud.mail.ru/public/2dxp/3sz8mjAib
Тест-3: cloud.mail.ru/public/3NjJ/ZYrfdTYrk
Тесты звучат интересно, по крайней мере, для маленького и большого квадратов (файлы 1 и 3) разница на слух хорошо ощутима. А вот форма фигур (1 и 2) практически не различается, так что тут тоже есть над чем подумать. Но в целом, звучание полученное с помощью FFT, на слух мне нравится больше.
Заключение
Данный тест, разумеется, не диссертация, а просто proof of concept, сделанный за несколько часов свободного времени. Но даже так, оно в принципе работает, и разницу ощущать на слух вполне реально. Я не знаю, можно ли научиться ориентироваться в пространстве по таким звукам, гипотетически наверно можно после некоторой тренировки. Хотя тут огромное поле для улучшений и экспериментов, например, можно использовать стереозвук, что позволит лучше разделять объекты с разных сторон, можно экспериментировать с другими способами конвертации изображения в звук, например, кодировать цвет разными частотами, и пр. И наконец, перспективным тут является использование 3d-камер, способных воспринимать глубину (увы, такой камеры в наличии нет). Кстати, с помощью несложного кода на OpenCV, вышеприведенный алгоритм можно адаптировать к использованию web-камеры, что позволит экспериментировать с динамическими изображениями.
Ну и как обычно, всем удачных экспериментов.
Изображение в звуки чтобы видеть
Изображение и звук могут дополнять друг друга в мире ощущений.
Так ученые разработали алгоритм когда слепой человек с рождения занимается удивительным новым хобби: фотографией. Его вновь обретенная возможность осуществляется благодаря системе, которая превращает изображение в последовательности звука.  Технология не только дает «зрение» для слепых, но также исследует организацию зрительной коры мозга человека. Эта технология гораздо сложнее чем музыкальная терапия.
Технология не только дает «зрение» для слепых, но также исследует организацию зрительной коры мозга человека. Эта технология гораздо сложнее чем музыкальная терапия.
Алгоритм преобразования изображения в звук
В 1992 году голландский инженер Питер Мейер создал алгоритм, который преобразует простые оттенки серого изображения в звуки. Система сканирует изображения слева направо, преобразуя изображения в звук. К примеру, диагональная линия простирается вверх по возрастанию по музыкальным нотам. В то время как более сложные изображения, сначала кажутся искажены шумом, но при достаточной подготовке, пользователи могут научиться “слышать” изображения.
В 2007 году невролог Амир Амеди и его коллеги в еврейском университете в Иерусалиме начали обучать тех, кто родился слепым, чтобы использовать голос. Несмотря на то, что не было визуальных ориентиров, после всего 70 часов обучения, люди начали от «слушания» простой точки и линии «видеть» всё изображение, например лица состоящие из 4500 пикселей (для сравнения, компьютерная игра на Nintendo Марио состояла из всего 192 пикселей). Путем присоединения камеры к компьютеру и наушников, слепые пользователи смогли даже перемещаться по комнате, только слыша звуковые сигналы. Каждые несколько шагов система преобразует изображение и звук, давая пользователям определить препятствия. Программа обучения также за несколько часов позволяет признавать человеческие силуэты, представленные звуком.
Когда исследователи сопоставили активность мозга участников, они нашли что-то удивительное. Общепринятая модель головного мозга состоявшая из областей, посвященных каждому чувству, например зрение ориентировано на зрительную кору. Исследователи давно догадывались, что если эти части не используются для их предполагаемого смысла, они многократно используются для других целей; например зрительная кора человека слепого от рождения может использоваться чтобы помочь повысить слух. Но ученые обнаружили, что области зрительной коры головного мозга, ответственные за отличия звуков интерпретировали человеческие силуэты.
Ученые подтвердили гипотезу, что проблемно ориентированные модели части головного мозга, ответственные за определенные аналогичные задачи — например, речи, чтения и языка тесно связаны вместе.
Части мозга зрительной коры обрабатывают не только визуальную информацию, но и могут работать с любой входящей информацией.